이번에는 그룹쿼리의 일종인 GROUPING SETS에 대해
다뤄보고자 한다. UNION ALL의 개념이 섞여 있어서
집합 연산자 내용과 함께 보면 좀 더 이해하기 수월한 개념이다.
2024.02.17 - [DB/SQL - Oracle] - [SQL] 집합 연산자 : UNION, UNION ALL, INTERSECT, MINUS
[SQL] 집합 연산자 : UNION, UNION ALL, INTERSECT, MINUS
SELECT 문으로 반환된 결과를 데이터 집합이라 한다. 이러한 데이터 집합(Set)을 연결하는 역할을 하는 것이 바로 집합 연산자(Set Operator)이다. 먼저 각 개념에 대해 살펴보고 예시를 통해 유의사항
bio-logisch.tistory.com
그룹 함수에 대한 개념과 앞서 다룬 ROLLUP과 CUBE에 대한 글도
미리 살펴보고 오면 GROUPING SETS절에 대해 이해하는데
도울이 될 수 있다!
2024.02.18 - [DB/SQL - Oracle] - [SQL] 그룹 함수 (1) ROLLUP(소그룹 간 소계 출력), CUBE(다차원 소계 출력)
[SQL] 그룹 함수 (1) ROLLUP(소그룹 간 소계 출력), CUBE(다차원 소계 출력)
먼저, 그룹 함수란 무엇인지 살펴보자. 그룹 합수(Group Funtion)는 테이블의 전체 행을 하나 이상의 컬럼을 기준으로 컬럼 값에 따라 그룹화하여 그룹별로 결과를 출력하는 함수를 말한다. 소계* 및
bio-logisch.tistory.com
GROUPING SETS 절
GROUPING SETS절은 ROLLUP이나 CUBE처럼 GROUP BY절에
명시해서 그룹 쿼리에 사용되는 절이다.
특정 항목에 대한 소계를 추출할 수 있고,
앞서 다룬 ROLLUP과 CUBE와 달리
어떤 항목에 대한 소계를 추출할지
그 항목을 직접 지정할 수 있다.
활용 구문은 다음과 같다.
SELECT 컬럼명1, ... , 집계함수
FROM 테이블명
[WHERE ... ]
GROUP BY [컬럼명1, ...] GROUPING SETS (컬럼명A, ...)
[HAVING ...]
[ORDER BY ... ]
개별 집계를 구할 수 있고, ROLLUP 계층구조와 달리
평등한 관계라 순서에 상관없이 동일한 결과를 추출할 수 있다.
GROUPING SETS(expr1, expr2, expr3)를
GROUP BY절에 명시했을 때, 괄호 안에 있는
세 표현식별로 각각 집계가 이루어진다.
즉, 쿼리 결과는
((GROUP BY expr1) UNION ALL (GROUP BY expr2)
UNION ALL (GROUP BY expr3))의 형태가 된다.
GROUPING SETS를 사용하여 여러 그룹화된 결과를
한 번에 검색하는 예시를 다뤄보고자 한다.
먼저, 고객 테이블에서 지역(region)과 성별(gender)에 따라 고객 수와
총 매출을 계산하고 싶다고 가정해보자.
// customers 테이블 생성
CREATE TABLE customers (
id INT,
name VARCHAR(50),
region VARCHAR(50),
gender VARCHAR(10),
sales DECIMAL(10, 2)
);
// 데이터 삽입
INSERT INTO customers VALUES (1, 'Alice', 'North', 'Female', 100.50);
INSERT INTO customers VALUES (2, 'Bob', 'South', 'Male', 200.75);
INSERT INTO customers VALUES (3, 'Charlie', 'East', 'Male', 150.25);
INSERT INTO customers VALUES (4, 'David', 'West', 'Male', 300.00);
INSERT INTO customers VALUES (5, 'Emma', 'North', 'Female', 120.00);
INSERT INTO customers VALUES (6, 'Frank', 'South', 'Male', 250.50);
INSERT INTO customers VALUES (7, 'Grace', 'East', 'Female', 180.75);
INSERT INTO customers VALUES (8, 'Henry', 'West', 'Male', 400.25);
INSERT INTO customers VALUES (9, 'Ivy', 'North', 'Female', 150.25);
INSERT INTO customers VALUES (10, 'Jack', 'South', 'Male', 220.50);
INSERT INTO customers VALUES (11, 'Kate', 'East', 'Female', 190.00);
INSERT INTO customers VALUES (12, 'Leo', 'West', 'Male', 280.75);
INSERT INTO customers VALUES (13, 'Mary', 'West', 'Female', 180.00);
INSERT INTO customers VALUES (14, 'Nick', 'North', 'Male', 210.25);
INSERT INTO customers VALUES (15, 'Olivia', 'South', 'Female', 240.50);
// 가정한 상황에 대한 SELECT문 실행
SELECT region, gender, COUNT(*) as customer_count, SUM(sales) as total_sales
FROM customers
GROUP BY GROUPING SETS ((region, gender), (region), (gender), ());
GROUPING BY절을 보면 고객을 총 4개의 그룹으로 나눴다.
- 첫 번째 그룹은 region과 gender에 따라 그룹화됨
- 두 번째 그룹은 region에만 따라 그룹화됨
- 세 번째 그룹은 gender에만 따라 그룹화됨
- 네 번째 그룹은 그룹화하지 않고 전체 집계를 나타냄
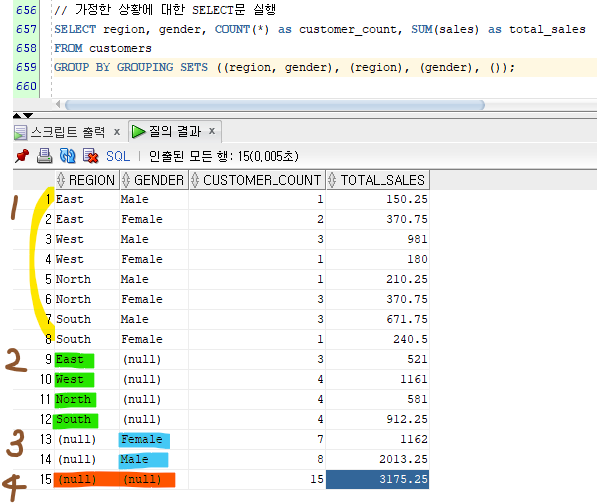
결과를 보면,
1. 각 지역별, 성별에 따른 고객 수와 총 매출,
2. 전체 지역에 대한 고객 수와 총 매출,
3. 전체 성별에 대한 고객 수와 총 매출,
4. 마지막으로 전체 고객 수와 총 매출을 계산한 결과가 나왔다.
'DB > SQL - Oracle' 카테고리의 다른 글
| [SQL] 날짜 데이터 타입 - date, timestamp (0) | 2024.02.19 |
|---|---|
| [SQL] 그룹 함수 (1) ROLLUP(소그룹 간 소계 출력), CUBE(다차원 소계 출력) (0) | 2024.02.18 |
| [SQL] 집합 연산자(Set Operator) - UNION, UNION ALL, INTERSECT, MINUS (0) | 2024.02.17 |
| [SQL] Sub-Query(서브쿼리) - 스칼라, 인라인 뷰, 중첩 서브쿼리 (0) | 2024.02.16 |
| [SQL] 조인(JOIN) - Inner join, outer join, cross join (1) | 2024.02.16 |