SELECT 문으로 반환된 결과를 데이터 집합이라 한다.
이러한 데이터 집합(Set)을 연결하는 역할을 하는 것이
바로 집합 연산자(Set Operator)이다.
먼저 각 개념에 대해 살펴보고 예시를 통해
유의사항에 대해서도 함께 다뤄보고자 한다.
집합 연산자의 개념과 특징
집합 연산자는 두 개 이상의 테이블에서
여러 개의 질의의 결과를 연결하여
하나로 결합하는 연산자를 말한다.
데이터 집합이 대상이므로 집합 연산자를 사용할 때
데이터 집합의 수는 한 개 이상을 사용할 수 있다.
즉, 여러 개의 SELECT문을 연결해
또 다른 하나의 쿼리를 만드는 역할을 한다고 볼 수 있다.
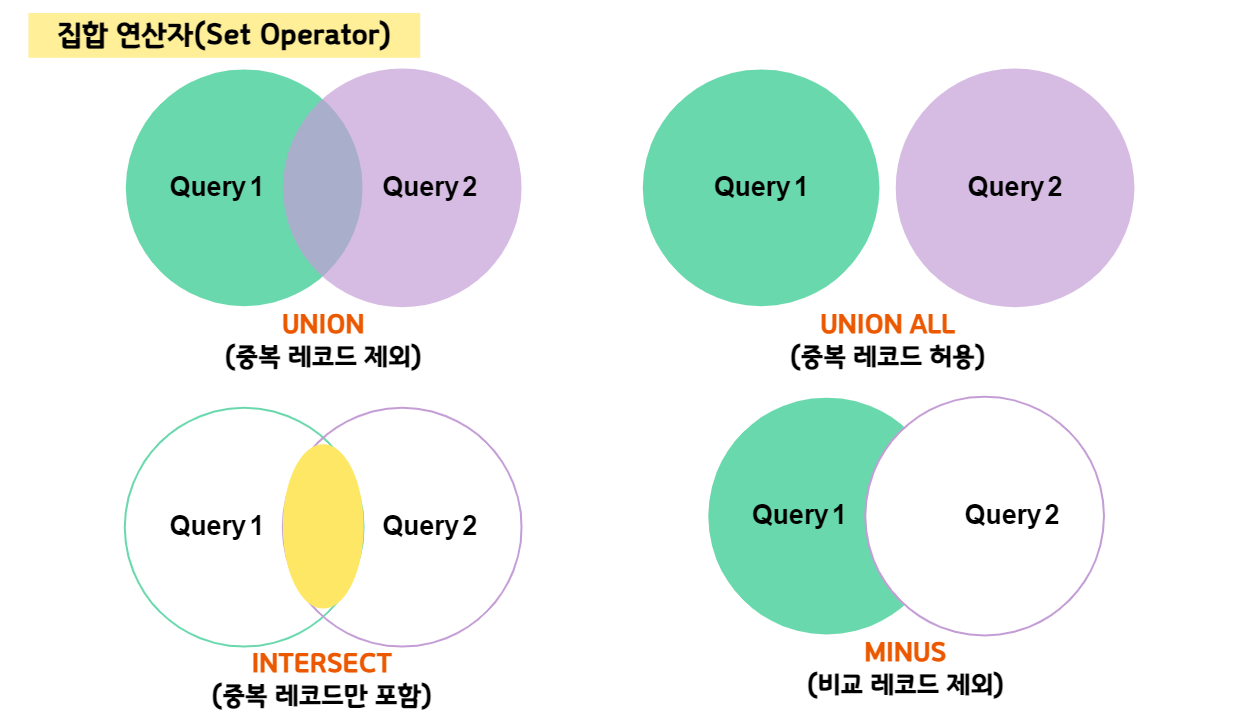
집합 연산자는 수학의 집합 개념과 같고,
합집합은 UNION, 대상 집합에서 중복된 건까지
모두 포함한 합집합은 UNION ALL,
교집합은 INTERSECT, 차집합은 MINUS에 해당한다.
여집합을 지칭하는 연산자가 따로 없지만
여집합에 해당하는 결과도 만들어 낼 수 있다.
UNION 합집합
UNION은 두 개의 데이터 집합의 결과에 대해
중복을 제거하고 모두 포함한 결과를 반환한다.

예시1
먼저 회원1번 테이블과 회원 2번 테이블을 생성하여
각각 3건씩 데이터를 삽입했다.
// 테이블 생성
CREATE TABLE customers1 (
id INT,
name VARCHAR(50),
email VARCHAR(50)
);
CREATE TABLE customers2 (
id INT,
name VARCHAR(50),
email VARCHAR(50)
);
// customers1 테이블에 데이터 삽입
INSERT INTO customers1 (id, name, email) VALUES (1, 'Alice', 'alice@example.com');
INSERT INTO customers1 (id, name, email) VALUES (2, 'Bob', 'bob@example.com');
INSERT INTO customers1 (id, name, email) VALUES (3, 'Charlie', 'charlie@example.com');
// customers2 테이블에 데이터 삽입
INSERT INTO customers2 (id, name, email) VALUES (3, 'Charlie', 'charlie@example.com');
INSERT INTO customers2 (id, name, email) VALUES (4, 'David', 'david@example.com');
INSERT INTO customers2 (id, name, email) VALUES (5, 'Emma', 'emma@example.com');
// UNION: 두 테이블의 고객 정보를 합쳐서 중복을 제거
SELECT * FROM customers1
UNION
SELECT * FROM customers2;
두 테이블에서 공통적으로 들어있어서
중복인 건인 Charlie라는 회원에 대한 튜플이
한 건만 들어갔다.
UNION ALL 합집합(중복 허용)
UNION ALL은 UNION과 유사하나
중복된 항목을 포함하여 결과를 반환한다.
결과를 보면 각 쿼리에 있는 중복값이
모두 포함되어 중복값이 두 번 포함되었다.

예시 2
이번에는 같은 상황에서 UNION에서
UNION ALL로 바꾸고 실행해보았다.
각 테이블에서 모두 Charlie라는 회원의 튜플이
중복 건에 해당하는데 합해진 그대로
두 건 모두 조회되었다.

INTERSECT 교집합
INTERSECT를 활용하면
두 쿼리문에서 공통된 부분만 추출된다.

예시 3
이번에는 INTERSECT를 사용하여
두 테이블, 즉 두 집합에서 공통된 부분만
조회되도록 실행했다. 쿼리문이 정상적으로
작동된다면 Charlie라는 회원에 대한
튜플 1건만 조회될 것이다.

MINUS 차집합
MINUS를 사용하면 데이터 집합을 기준으로
다른 데이터 집합과 공통 항목을 제외한 결과만 추출해 낸다.

예시 4
customers1 테이블을 기준으로 MINUS 연산자가
실행되는 것이므로 customers1 테이블과 customers2 테이블에서
중복된 건인 Charlie에 대한 건만 삭제되고
남은 customers1 테이블의 튜플이 조회된다.

집합 연산자 자체는 그렇게 복잡하지는 않지만,
실제로 사용하려면 제한사항이 있어서
막히는 경우가 발생하기도 했다.
그 부분에 대해서도 점검해보고자 한다.
집합 연산자의 제한사항
1) 집합 연산자로 연결되는 각 SELECT문의 SELELCT 리스트 개수와 데이터 타입은 일치해야 한다.
상황 1
하지만 첫 번째 SELECT문에서는 ID와 NAME 컬럼만 조회하고
두 번째 SELECT문에서는 NAME과 EMAIL 컬럼만 조회한다면
어떻게 될까?
오류가 발생한다!

위의 경우에는 각 SELECT문에서 조회하고자 하는
리스트의 개수가 2개로 같았다.
하지만 연결되는 컬럼의 데이터 타입이 달라서 오류가 발생했다.
조회하고자 하는 컬럼이 집합 연산자에 의해 비교될 때는
customers1테이블의 id컬럼과
customers2테이블의 name컬럼이 매칭될 것이다.
이어서 두 번째의 경우도 각각 name 컬럼과 email컬럼이
같은 데이터 타입이어야 둘의 중복여부를 비교할 수 있을 것이다.
두 테이블을 생성할 때 , id컬럼의 속성은 INT였고
name과 email컬럼의 속성은 VARCHAR2(50)였다.
따라서customers1테이블의 id컬럼과
customers2테이블의 name컬럼의 데이터 타입이
서로 다르기 때문에 오류가 발생했다.
상황 2
사실은 name컬럼과 email컬럼은
데이터 타입은 같지만 서로 비교하려는 컬럼은
아니기에 그 자체로 문제가 될 수는 있지만
데이터 타입이 일단 같으므로 집합 연산자를
실행할 때는 각각 name과 email컬럼 한 건에 대한
조회를 실행하는 SELECT문이었다면,
오류가 발생하지는 않는다. 결과를 살펴보자.

결과를 보면 말 그대로 customers1테이블의 name컬럼의 값 리스트와
customers2테이블의 email컬럼의 값 리스트가 합해져 나오는 결과가 출력되었다.
만약 이 결과를 의도한 것이 아니라면 문제가 될 수 있다.
이 문제를 해결하려면,
모든 컬럼에 대해 조회하는 SELECT문으로 수정하거나,
id와 name으로 통일하는 등 상황에 맞게 고려하여
각각 SELECT문에서 같은 컬럼에 대해 조회해야 한다.
그래야 중복되는지 아닌지 데이터베이스가 비교할 수 있고
동시에 정확히 매칭되는 값을 비교한 결과를 출력할 수 있기 때문이다.
상황 3
각 SELECT문에서 조회하려는 컬럼의 개수가 상이하면 어떻게 될까?

역시 오류가 발생한다.
이런 경우에도 두 번째 SELECT문에서 name컬럼을 제외해야 한다.
아니면 첫 번째 SELECT문에 name컬럼을 추가하는 방법도 가능하다.
후자의 방법으로 다시 수정해서 쿼리를 실행해보았다.

이 경우에는 오류는 발생하지 않았고, 예상한대로 중복된 건인
3번 회원인 Charlie에 대한 튜플이 하나 제외되고 출력되었다.
참고할 사항은 이렇게 각 SELECT문에 2개 이상의 컬럼을 지정하여
집합 연산자를 쓸 때는 해당 컬럼들의 값이 모두 같은 경우에만
중복건으로 본다는 점이다.
따라서 만약 customers2테이블에 id가 6이고, name의 값이 Bob이라는 데이터가 저장되어도
customers1테이블의 id가 2이고 name컬럼의 값이 Bob인 튜플과는 중복 건으로 인식하지 않는다.

하지만, 아래와 같이 쿼리문을 실행하면 이름이 Bob인 값이 중복되었다고 보고
Bob이라는 이름을 가진 회원의 값이 중복건으로 처리되어서 1건만 조회되었다.

둘이 동명이인이라면 사실 Bob이라는 이름의 회원이 2건으로 나와야 하지만
이 경우에는 그렇지 않아서 문제가 발생할 수 있다.
따라서 회원리스트와 같이 동명이인이 있을 수 있어서
이름에 중복값이 있을 수 있는 컬럼의 경우 해당 컬럼만으로
집합 연산자를 사용하는 쿼리문으로 조회를 하면
누락된 조회 건이 발생할 수 있게 된다.
이런 문제를 해결하려면 INTERSECT로 다시 중복건으로 처리된 튜플을
역추적해나가면서 확인해야 한다.
2) 집합 연산자로 SELECT문을 연결할 때 ORDER BY절은 맨 마지막 문장에서만 사용할 수 있다.
상황 4
각 SELECT문에서 ORDER BY절로 정렬된 상태에서
집합연산자로 된 쿼리문을 실행하면 어떻게 될까?

오류가 발생한다..!
이유는.. 그것이 문법적인 룰이라는 점..밖에 찾지 못했다.
아래와 같이 맨 마지막 문장에만 ORDER BY절을 추가했더니
그 기준에 맞게 정렬되어 출력되었다.

3) BLOB, CLOB, BFILE 타입의 컬럼에 대해서는 집합 연산자를 사용할 수 없다.
4) UNION, INTERSECT, MINUS 연산자는 LONG형 컬럼에는 사용할 수 없다.
3)과 4)의 내용은 따로 특정 타입의 컬럼에서 집합 연산자를
사용하지 못한다는 명확한 룰이 있어서 따로 증명하지는 않았다.
제한사항 정리
집합 연산자의 제한사항
1) 집합 연산자로 연결되는 각 SELECT문의 SELELCT 리스트 개수와 데이터 타입은 일치해야 한다.
2) 집합 연산자로 SELECT문을 연결할 때 ORDER BY절은 맨 마지막 문장에서만 사용할 수 있다.
3) BLOB, CLOB, BFILE 타입의 컬럼에 대해서는 집합 연산자를 사용할 수 없다.
4) UNION, INTERSECT, MINUS 연산자는 LONG형 컬럼에는 사용할 수 없다.
'DB > SQL - Oracle' 카테고리의 다른 글
| [SQL] 그룹 함수 (1) ROLLUP(소그룹 간 소계 출력), CUBE(다차원 소계 출력) (0) | 2024.02.18 |
|---|---|
| [SQL] 그룹 함수 (2) GROUPING SETS(특정 항목에 대한 소계 출력) (0) | 2024.02.18 |
| [SQL] Sub-Query(서브쿼리) - 스칼라, 인라인 뷰, 중첩 서브쿼리 (0) | 2024.02.16 |
| [SQL] 조인(JOIN) - Inner join, outer join, cross join (1) | 2024.02.16 |
| [SQL] DML(데이터 조작어) - select *order by* 정렬 + ASCII(아스키코드) + UNICODE(유니코드) (0) | 2024.02.16 |